
Deduplication 구현에서 가장 중요한 것은 Dedup Table이다. Table에서 fingerprint가 같은 것이 있는지를 확인하고 같은 것이 있다면 저장하지 않는 것이 간단하면서도 중요한 아이디어이다. 하지만 NVMM의 특성상 Search가 빠르지 않기 때문에 이를 도와주기 위해 DRAM에 추가적인 자료구조가 필요하다. NOVA에서 이미 사용하고 있는 Radix-Tree를 사용하기로 하였다. 결국 이 Radix Tree는 File System전체에 하나가 있는 것이다. 그렇다면 이에 대한 접근, 즉 선언은 어디에 해야 되는 것일까?
실제 Table은 root file로 생성하기로 정했다. 그렇다면 Radix tree의 참조는...음...NOVA에 nova_sb_info라는 구조체가 있다. 이 구조체는 super-block에 대한 정보를 DRAM에서 저장해놓은 것이라고 한다. 이 구조체가 어떻게 사용되느냐에 따라서 여기에 Radix Tree를 선언해놔도 되지 않을까?
/*
* NOVA super-block data in DRAM
*/
struct nova_sb_info {
struct super_block *sb; /* VFS super block */
struct nova_super_block *nova_sb; /* DRAM copy of SB */
struct block_device *s_bdev;
struct dax_device *s_dax_dev;
/*
* base physical and virtual address of NOVA (which is also
* the pointer to the super block)
*/
phys_addr_t phys_addr;
void *virt_addr;
void *replica_reserved_inodes_addr;
void *replica_sb_addr;
unsigned long num_blocks;
/* TODO: Remove this, since it's unused */
/*
* Backing store option:
* 1 = no load, 2 = no store,
* else do both
*/
unsigned int nova_backing_option;
/* Mount options */
unsigned long bpi;
unsigned long blocksize;
unsigned long initsize;
unsigned long s_mount_opt;
kuid_t uid; /* Mount uid for root directory */
kgid_t gid; /* Mount gid for root directory */
umode_t mode; /* Mount mode for root directory */
atomic_t next_generation;
/* inode tracking */
unsigned long s_inodes_used_count;
unsigned long head_reserved_blocks;
unsigned long tail_reserved_blocks;
struct mutex s_lock; /* protects the SB's buffer-head */
int cpus;
struct proc_dir_entry *s_proc;
/* Snapshot related */
struct nova_inode_info *snapshot_si;
struct radix_tree_root snapshot_info_tree;
int num_snapshots;
/* Current epoch. volatile guarantees visibility */
volatile u64 s_epoch_id;
volatile int snapshot_taking;
int mount_snapshot;
u64 mount_snapshot_epoch_id;
struct task_struct *snapshot_cleaner_thread;
wait_queue_head_t snapshot_cleaner_wait;
wait_queue_head_t snapshot_mmap_wait;
/* DAX-mmap snapshot structures */
struct mutex vma_mutex;
struct list_head mmap_sih_list;
/* ZEROED page for cache page initialized */
void *zeroed_page;
/* Checksum and parity for zero block */
u32 zero_csum[8];
void *zero_parity;
/* Per-CPU journal lock */
spinlock_t *journal_locks;
/* Per-CPU inode map */
struct inode_map *inode_maps;
/* Decide new inode map id */
unsigned long map_id;
/* Per-CPU free block list */
struct free_list *free_lists;
unsigned long per_list_blocks;
};이를 알아보기 위해서 익숙한 free_list를 살펴보았다. write path에서 파일의 Super block에 접근해서 free page를 받아온다. 하지만 free page라는 것은 VFS단계의 Super block에는 없는 것이고 nova file system의 super block에만 있는 것이다. nova file system specific information인 것이다. 이는 DRAM에만 저장되어 있는 것 같았고 이게 바로 nova_sb_info였다. 밑에 코드를 보면 super_block은 VFS의 super block이고 이 구조체의 s_fs_info포인터를 반환해주는 것을 nova_sb_info로 하고 있다. <fs.h>에 가보면 s_fs_info는 filesystem private info라고 한다.
static inline struct nova_sb_info *NOVA_SB(struct super_block *sb)
{
return sb->s_fs_info;
}그렇다면 나도 dedup과정에서 처음에는 VFS super block으로 접근하다가, NOVA_SB() 를 사용하여 nova_sb_info를 읽어온 뒤, 그 안에 선언된 Radix tree를 타면 되지 않을까? 좋다~. 그럼 nova_sb_info가 어디서 초기화되는지도 알아야 된다. 이는 <fs/nova/super.c>에서 살펴본다.
nova_fill_super에서 free_lists를 채워주는 부분은 없다...다른 모든 부분은 세팅하는데 이 부분은 어디서 세팅하는 걸까? balloc.c 에서 찾을 수 있었다.
int nova_alloc_block_free_lists(struct super_block *sb)
{
struct nova_sb_info *sbi = NOVA_SB(sb);
struct free_list *free_list;
int i;
sbi->free_lists = kcalloc(sbi->cpus, sizeof(struct free_list),
GFP_KERNEL);
if (!sbi->free_lists)
return -ENOMEM;
for (i = 0; i < sbi->cpus; i++) {
free_list = nova_get_free_list(sb, i);
free_list->block_free_tree = RB_ROOT;
spin_lock_init(&free_list->s_lock);
free_list->index = i;
}
return 0;
}미리 세팅한 sbi를 읽어오고, free_list라는 자료구조를 만든다. GFP_KERNEL flag를 사용했으니까 Process가 sleep 될 수 있으며 항상 allocated 된 메모리를 반환하겠다. nova_get_free_list는 또 뭐냐. 몇 번째 CPU의 free list인지 반환해주는 것 같다. 잠깐, 그럼 이것도 그냥 선언이지, 안의 내용을 채우는 건 아니네?
static void nova_init_free_list(struct super_block *sb,
struct free_list *free_list, int index)
{
struct nova_sb_info *sbi = NOVA_SB(sb);
unsigned long per_list_blocks;
per_list_blocks = sbi->num_blocks / sbi->cpus;
free_list->block_start = per_list_blocks * index;
free_list->block_end = free_list->block_start +
per_list_blocks - 1;
if (index == 0)
free_list->block_start += sbi->head_reserved_blocks;
if (index == sbi->cpus - 1)
free_list->block_end -= sbi->tail_reserved_blocks;
nova_data_csum_init_free_list(sb, free_list);
nova_data_parity_init_free_list(sb, free_list);
}이제 진짜 찾았다. block의 수를 cpu의 수로 나눠서 시작 주소와 끝 주소를 설정해준다. 그리고 가장 마지막과 첫 cpu에게는 block의 head와 tail을 reserving된 block만큼 감소시킨다. 그다음 오류를 위한 csum과 parity를 해주는 것 같다. free_list start과 end만 있으면 되냐? 이건 또 다른 문제니까 일단 이렇게 선언이 되고 어디서 호출이 되는가를 찾아야 된다.
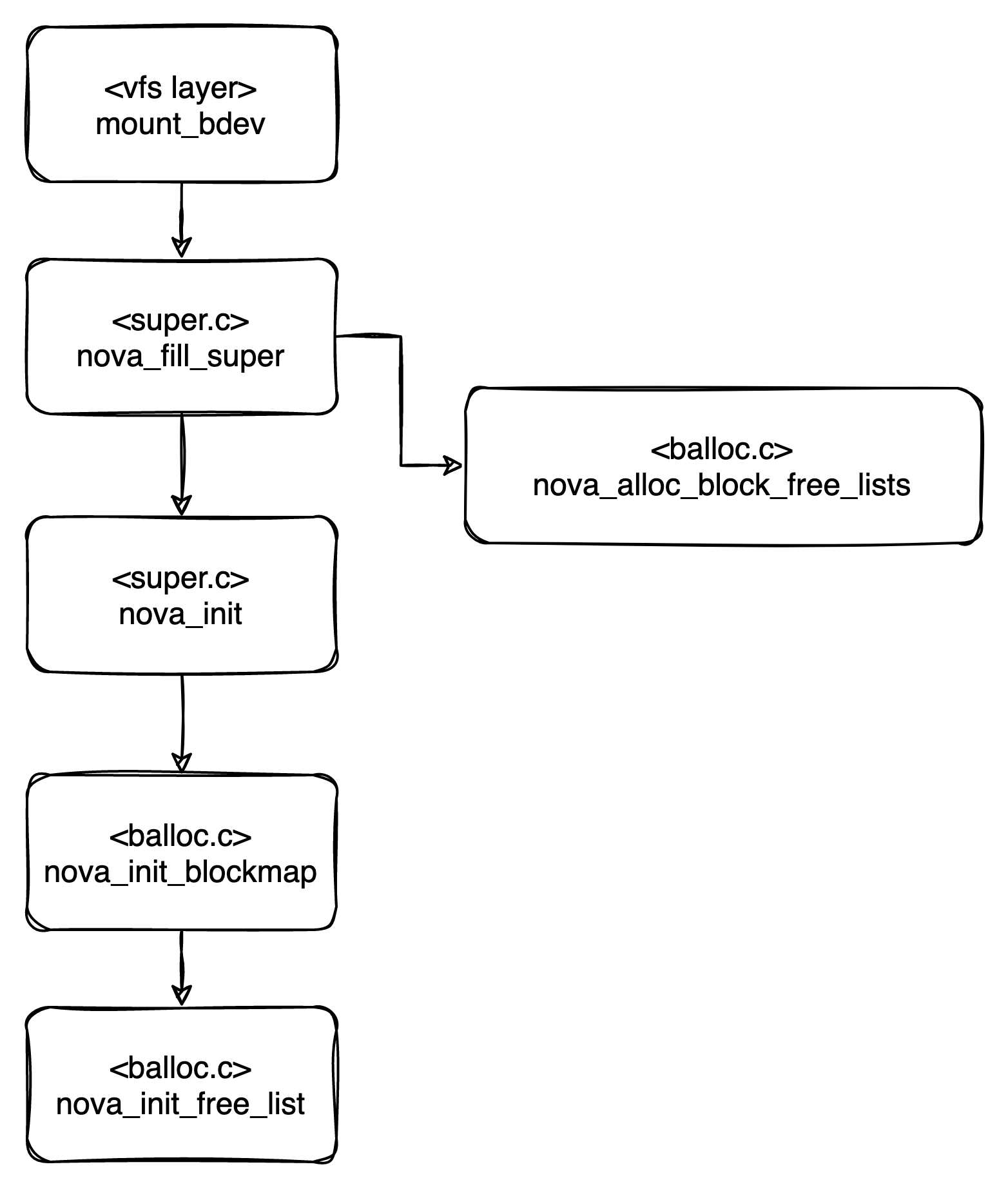
앞에서 삽질한 것들의 결과가 다음과 같았다. 즉, nova_fill_super에서 nova_sb_info를 채워주는 것이고, 여기에 Radix tree를 초기화해주는 무언가를 넣어주면 되지 않을까라는 생각이 들었다.
여기서 또 한가지 고민이 든다. 이제 nova_sb_info에 radix tree를 추가하는 것이 맞는 건 확실한데, 그 초기화를 nova_fill_super에서 때려야 될까? nova_init에서 때려야 될까?
괜히 에러 만들지말고,
nova_fill_super -> Radix Tree 선언
nova_init -> 기존 파일을 읽어서 Radix Tree rebuilding
로 해야겠다. 우선 Radix Tree에 대한 이해도가 낮기 때문에 nova_fill_super에서 선언을 하고 dedup system call을 통해 build , read까지 해봐야겠다.
'DeNOVA Test' 카테고리의 다른 글
| 7. Dedup Queue 선언해보기(dedup-queue 1부) (0) | 2021.07.21 |
|---|---|
| 6. Radix Tree추가해보기 2부 (실제 코딩) (0) | 2021.07.20 |
| 4. Module 수정 + test (0) | 2021.07.17 |
| 3. Test system call 추가 (0) | 2021.07.17 |
| 2. NOVA fs mounting (0) | 2021.07.17 |